Weather-Dependent Industries

Dive into the critical role weather plays across various industries and how it affects operational decisions and financial outcomes.


Articles, videos, and documentation to help you get the most from Visual Crossing Weather
Learn about some of the ways people are using Visual Crossing Weather Data
Dive into the critical role weather plays across various industries and how it affects operational decisions and financial outcomes.

A consistent energy supply is critical to maintaining a functioning society. Medical services, production, refrigeration, and entertainment all rely on power plants to satisfy their electricity demand. However, sometimes the weather’s energy conflicts with power production. Extreme heat, very low temperatures, and extreme wind speeds can all both increase power demand and reduce energy output, …

In an ad-saturated world, businesses need to deliver timely and relevant messages that match a consumer’s mood and needs. One factor of a data-driven approach to marketing messages is weather-based advertising, which uses real-time weather data to develop creative messaging. Leveraging weather APIs like VisualCrossing can make a huge impact on your conversion rate when …

From sourcing accurate data to implementing user-friendly interfaces, discover step-by-step instructions and best practices to build a weather app.

Discover the significance of World Meteorological Day, celebrated annually to honor the contributions of climate science and weather awareness to society.

Explore the essentials of degree days, types, and how to calculate them, as well as their applications in energy management and agriculture.
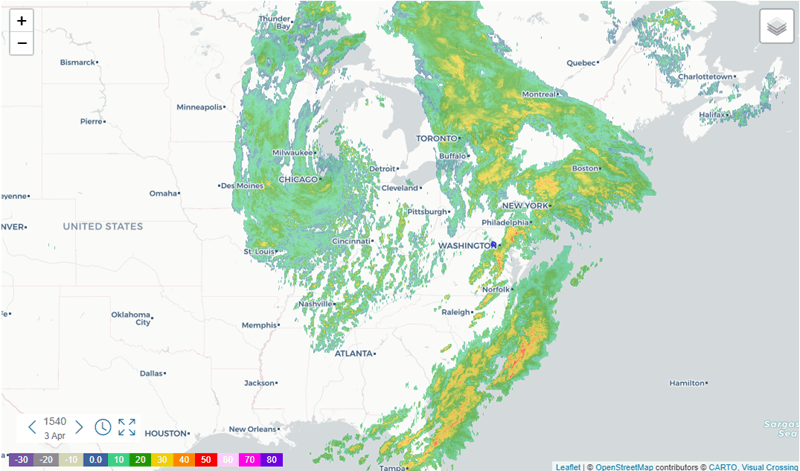
Explore the transformative power of weather data visualization in presenting complex meteorological information in an accessible and engaging way.

The year 2023 broke the record for being the warmest year in our history and humans are a prominent reason for it. This should be a major concern in the climate of our earth and everything in it. Even Antarctica, which has long been seen as an icy stronghold, is feeling the effects of this …

Floods are a common and sometimes severe natural disaster that can occur anywhere, putting people and communities at serious risk of severe harm. In United States, flooding is the most prominent natural disaster. A slew of atmospheric rivers devastated California in February 2024. Severe winds, flash floods, and extensive power outages are the result of …

Meteorologists and weather enthusiasts alike may be perplexed by the complex vocabulary used to characterize different atmospheric phenomena. Every meteorological term, from the enthralling Pineapple Express to the terrifying Bomb Cyclones, reveals a different aspect of the planet’s changing climate. This article explores the phenomena of atmospheric rivers, bomb cyclones, supercell thundersnow, Pineapple Express, and …
Continue reading “Atmospheric Rivers, Bomb Cyclones and Other Weird Weather Words, Explained”